모델 서빙
모델 서비스
참고
이 기능은 엔터프라이즈 전용 기능입니다.
Backend.AI(백엔드닷에이아이)에서는 모델 학습 단계의 개발 환경 구축 및 자원 관리를 쉽게 해주는 것뿐만 아니라, 모델을 완성한 후 추론 서비스로 배포하고자 할 때에 최종 사용자(예: AI 기반 모바일 앱 및 웹서비스 백엔드 등)가 추론 API를 호출할 수 있게 하는 모델 서비스* 기능을 23.09 버전부터 정식 지원합니다.
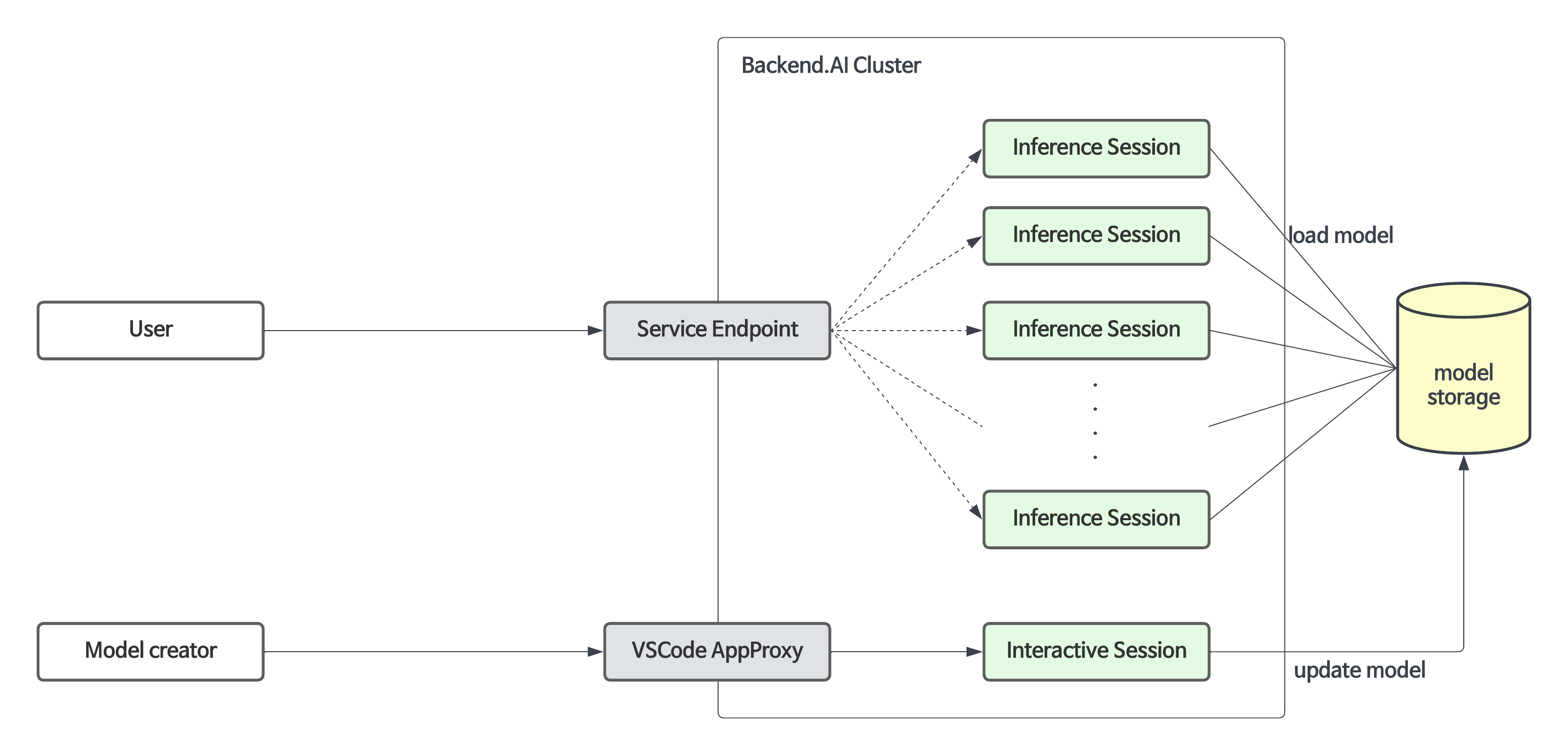
모델 서비스는 기존의 학습용 연산 세션 기능을 확장하여, 자동화된 유지·보수 및 스케일링을 가능하게 하고 프로덕션 서비스를 위한 영구적인 포트 및 엔드포인트 주소 매핑을 제공합니다. 개발자나 관리자가 연산 세션을 수동으로 생성·삭제할 필요 없이 모델 서비스에 필요한 스케일링 파라미터를 지정해주기만 하면 됩니다.
23.03 및 이전 버전에서 모델 서비스를 구성하는 방법과 한계
모델 서빙에 특화된 모델 서비스 기능은 23.09에서 정식 지원하지만, 그 이전 버전들에서도 제한적인 모델 서비스 기능을 활용할 수 있습니다.
예를 들어, 23.03 버전에서는 다음과 같은 방법으로 학습용 연산 세션을 변용하여 모델 서비스를 구성할 수 있습니다:
세션 생성시 사전 개방 포트를 추가해서 모델 서빙을 위한 세션 내 실행중인 서버 포트와 매핑하도록 설정(사전 개방 포트 사용법에 대한 설명은 세션 생성하기 전에 사전 개방 포트를 추가하는 방법 을 참고하십시오.)
Open app to public체크하여 사전 개방된 포트에 매핑된 서비스를 외부로 공개하도록 설정(Open app to public 에 대한 자세한 설명은 Open app to public 를 참고하십시오.)
대신 23.03 버전에서는 다음과 같은 제한 사항들이 있습니다:
세션이 외부 요인(유휴 시간 만료, 시스템 오류 등)으로 종료될 경우 자동으로 복구되지 않습니다.
세션을 새로 실행할 때마다 앱 포트가 변경됩니다.
세션을 반복적으로 재실행할 경우, 유휴 포트가 고갈될 수 있습니다.
23.09의 정식 모델 서비스 기능은 위와 같은 제한 사항들을 해결합니다. 따라서 23.09 버전부터는 가급적 모델 서빙 메뉴를 통해 모델 서비스를 생성·관리하는 것이 좋습니다. 사전 개방 포트 기능을 활용하는 방법은 개발 및 테스트 과정에서만 사용하는 것을 권장합니다.
모델 서비스를 사용하기 위한 단계 안내
모델 서비스를 사용하기 위해서는 크게 아래와 같은 단계를 따라야 합니다:
모델 정의 파일 생성하기
모델 정의 파일을 모델 타입 폴더에 업로드하기
모델 서비스 생성하기·수정하기
(모델 서비스가 공개되지 않은 경우) 토큰 발급하기
(엔드유저 전용) 모델 서비스에 대응하는 엔드포인트에 접속하여 서비스 확인하기
모델 정의 파일 생성하기
참고
모델 정의 파일은 현재 버전 기준으로
model-definition.yml, 또는model-definition.yaml로 파일명과 확장자를 고정해야 합니다.
모델 정의 파일은 Backend.AI 시스템이 추론용 세션을 자동으로 시작, 초기화하고 필요에 따라 스케일링할 때 필요한 설정 정보를 담고 있는 파일입니다. 이 파일을 추론 서비스 엔진을 담고 있는 컨테이너 이미지와는 독립적으로 모델 타입 폴더에 저장합니다. 이를 통해 모델을 실행하는 엔진이 다양한 모델을 필요에 따라 바꿔가며 서비스할 수 있도록 하며, 모델이 변경될 때마다 컨테이너 이미지를 새로 빌드 및 배포하지 않아도 되도록 해줍니다. 네트워크 스토리지에서 직접 모델 정의와 모델 데이터를 불러오므로, 자동 스케일링 시 배포 과정을 더 단순화 및 효율화할 수 있습니다.
모델 정의 파일은 다음과 같은 형식을 따릅니다:
models:
- name: "simple-http-server"
model_path: "/models"
service:
start_command:
- python
- -m
- http.server
- --directory
- /home/work
- "8000"
port: 8000
health_check:
path: /
max_retries: 5
모델 정의 파일에 대한 키-값 설명
참고
“(필수)” 항목이 기재되어 있지 않은 항목은 선택 입력입니다.
name(필수): 모델 명을 정의합니다.model_path(필수): 모델이 정의된 경로를 지정합니다.service: 서비스할 파일(명령어 스크립트, 코드 포함)에 대한 정보를 정리해두는 항목입니다.pre_start_actions:start_command항목 내 명령어 이전에 실행되어야 할 명령어 또는 액션을 정리해두는 항목입니다.start_command(필수): 모델 서빙시 실행할 명령어를 지정합니다.port(필수): 모델 서빙시 실행할 명령어에 대응해 컨테이너 기준 열어둘 포트를 지정합니다.health_check: 서비스가 지정된 기간마다 에러 없이 실행되고 있는지 확인하는 항목입니다.path: 모델 서빙시 서비스가 제대로 실행되고 있는지를 확인하는 경로를 지정합니다.max_retries: 모델 서빙시 서비스에 요청이 간 뒤, 응답이 오지 않았을 때 재시도를 몇 번 할 것인지 지정합니다.
Backend.AI 모델 서빙에서 지원하는 서비스 액션 안내
write_file: 입력받은 파일 명으로 파일을 생성, 내용을 추가하는 액션입니다.mode값에 아무것도 적지 않을 경우 기본 접근 권한은644입니다.arg/filename: 파일명을 적습니다.body: 파일에 추가할 내용을 적습니다.mode: 파일의 접근권한을 적습니다.append: 파일에 내용 덮어쓰기/덧붙이기 설정을True/False로 적습니다.
write_tempfile: 임시파일명(확장자는.py)을 갖는 파일을 생성, 내용을 추가하는 액션입니다.mode값에 아무것도 적지 않을 경우 기본 접근 권한은644입니다.body: 파일에 추가할 내용을 적습니다.mode: 파일의 접근권한을 적습니다.
run_command: 명령어를 실행한 결과(오류포함)를 아래와 같은 형태로 반환하게 됩니다.(out: 명령어 실행 결과,err: 명령어 실행 중 오류 발생시 출력되는 오류 메시지)args/command: 실행할 명령어를 배열형태로 적습니다. (e.g.python3 -m http.server 8080명령어는 [”python3“, ”-m“, ”http.server“, ”8080“])
mkdir: 입력한 경로에 따라 디렉토리를 생성하는 액션입니다.args/path: 디렉토리를 만들 경로를 지정합니다.
log: 입력한 메시지에 따라 로그를 출력하는 액션입니다.args/message: 로그에 표시할 메시지를 적습니다.debug: 디버그 모드인 경우True, 아닌 경우False로 적습니다.
모델 정의 파일을 모델 타입 폴더에 업로드하기
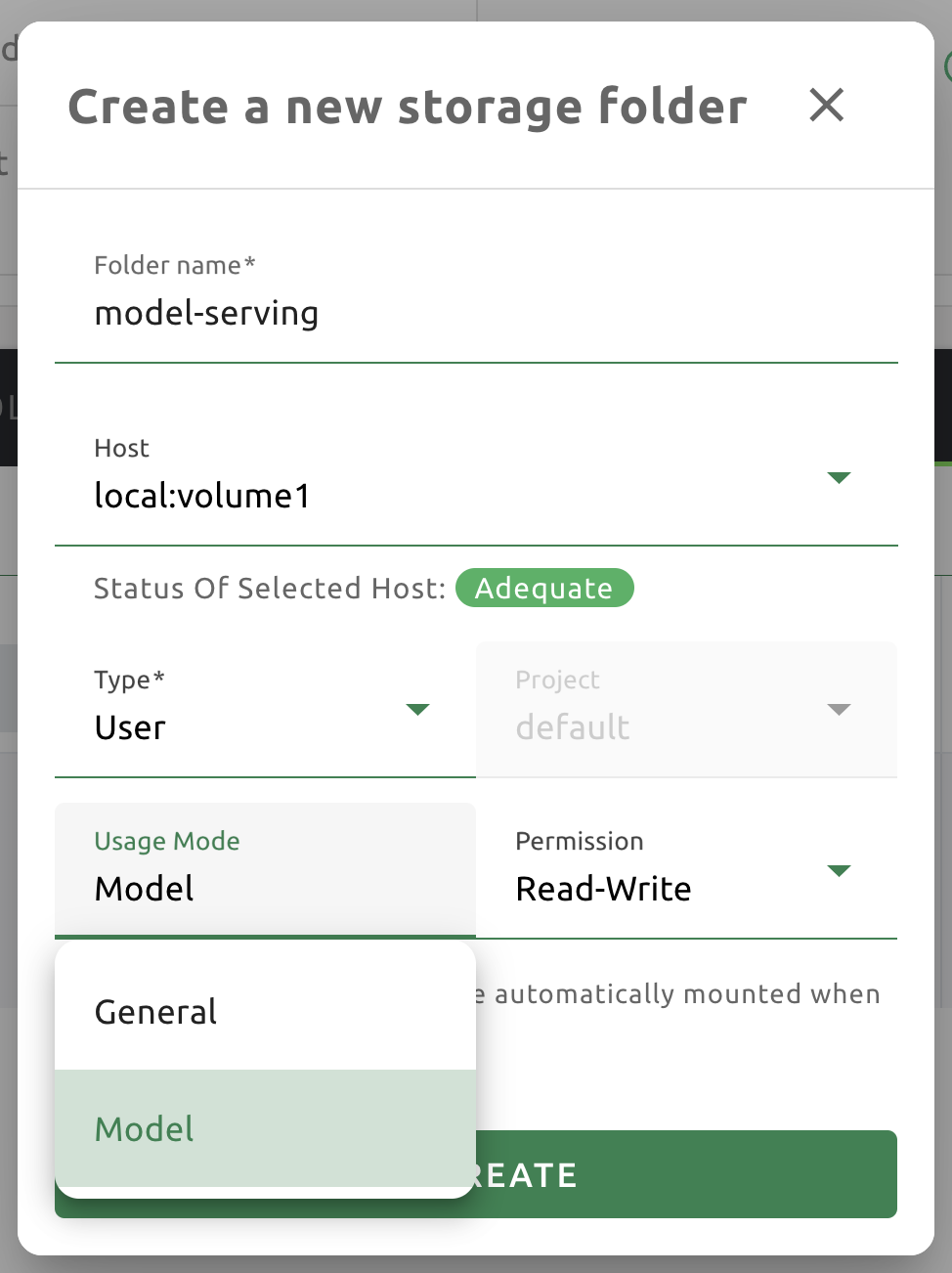
모델 정의 파일(model-definition.yml) 을 모델 타입 폴더에 업로드하기 위해서는 가상 폴더를 생성해야 합니다. 이 때, 가상폴더 생성시 타입은 일반 이 아닌 모델 타입으로 선택하여 생성합니다. 생성하는 방법은 데이터 & 폴더 활용하기의 Storage 폴더 생성 부분을 참고하십시오.
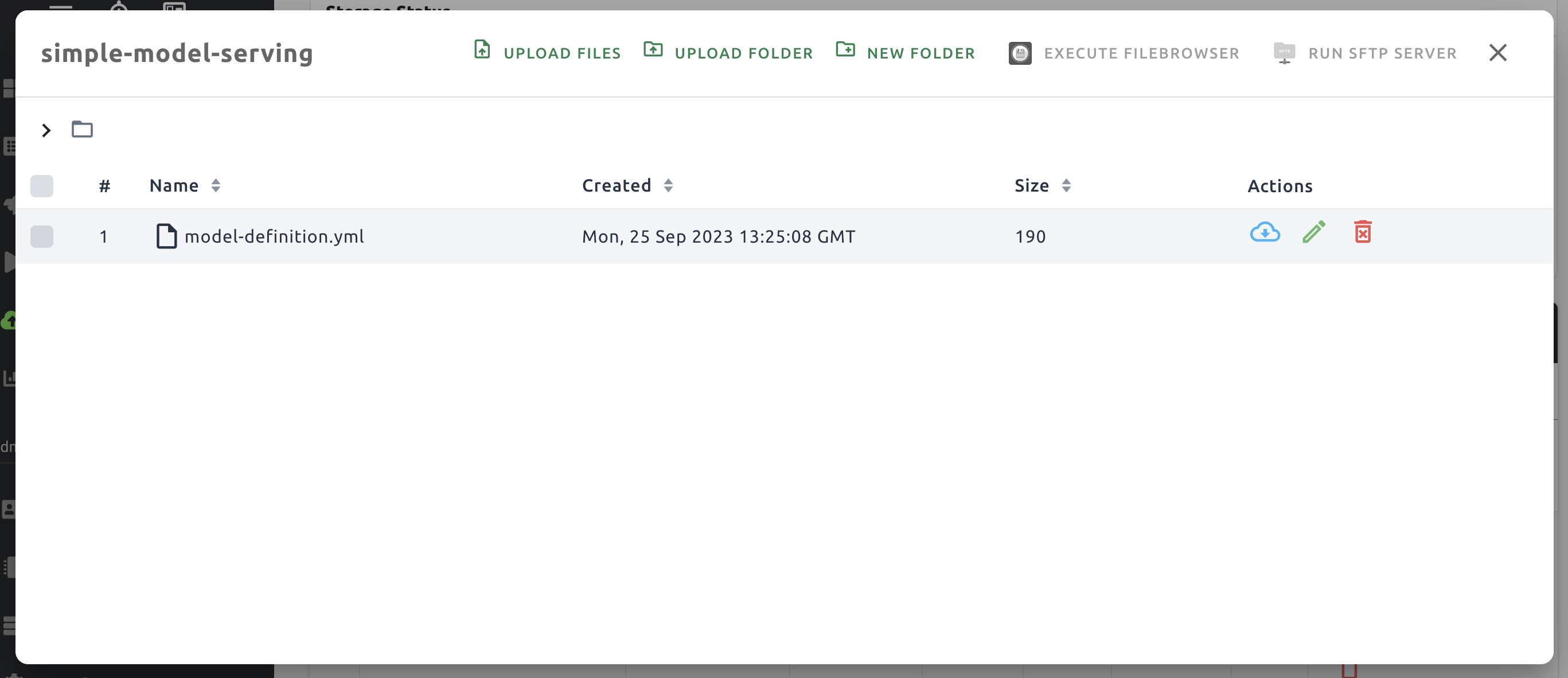
폴더를 생성한 뒤, 데이터 & 폴더 페이지에서 모델 탭을 선택, 방금 생성한 모델 타입 폴더 아이콘을 클릭하여 폴더 탐색기를 엽니다. 이후 모델 정의 파일을 업로드 합니다.
모델 서비스 생성하기/수정하기
모델 정의 파일까지 모델 타입의 가상 폴더에 업로드가 완료되었으면 본격적으로 모델 서비스를 생성할 준비가 되었다고 할 수 있습니다.
모델 서빙 페이지에서 “서비스 시작하기” 버튼을 클릭해주세요. 이후 서비스 생성에 필요한 설정을 입력하는 모달이 뜨게 됩니다.
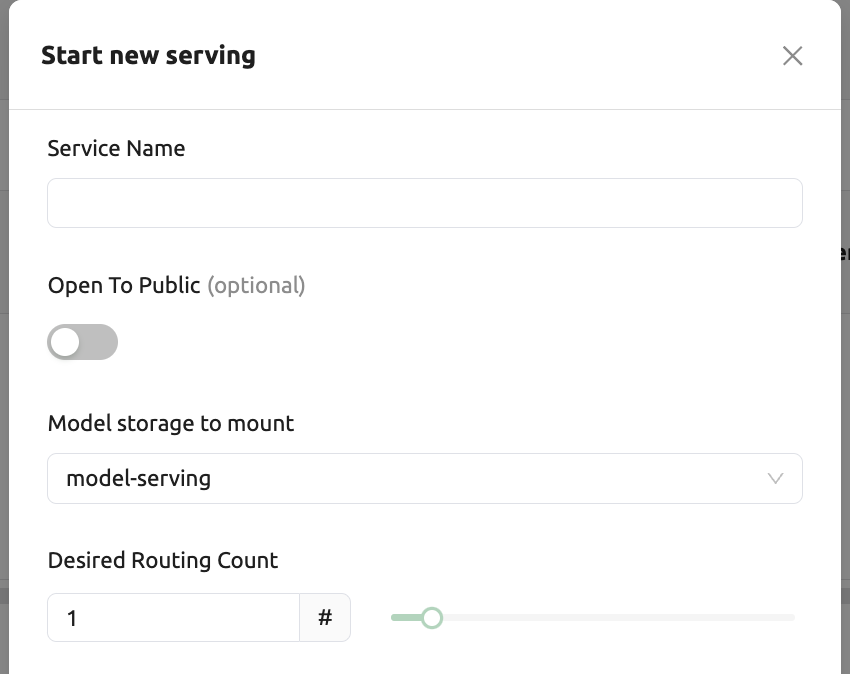
우선 서비스 이름과 모델 서비스에 사용할 모델 타입의 가상 폴더를 선택합니다.
각 항목에 대한 자세한 설명은 다음을 참고 하십시오.
Open To Public: 모델 서비스 생성후 서비스하고자 하는 서버에 별도의 토큰이 없이도 접근할 수 있도록 하는 옵션입니다. 기본은 비활성화되어 있습니다.
Desired Routing Count: 모델 서비스에서 서비스하고자 하는 서버가 여러 개가 될 수 있습니다. 이때 라우팅, 현재 기준으로 서비스하려는 세션을 몇 개까지 만들어야 할지 설정하는데, 이 값을 기준으로 하게 됩니다.
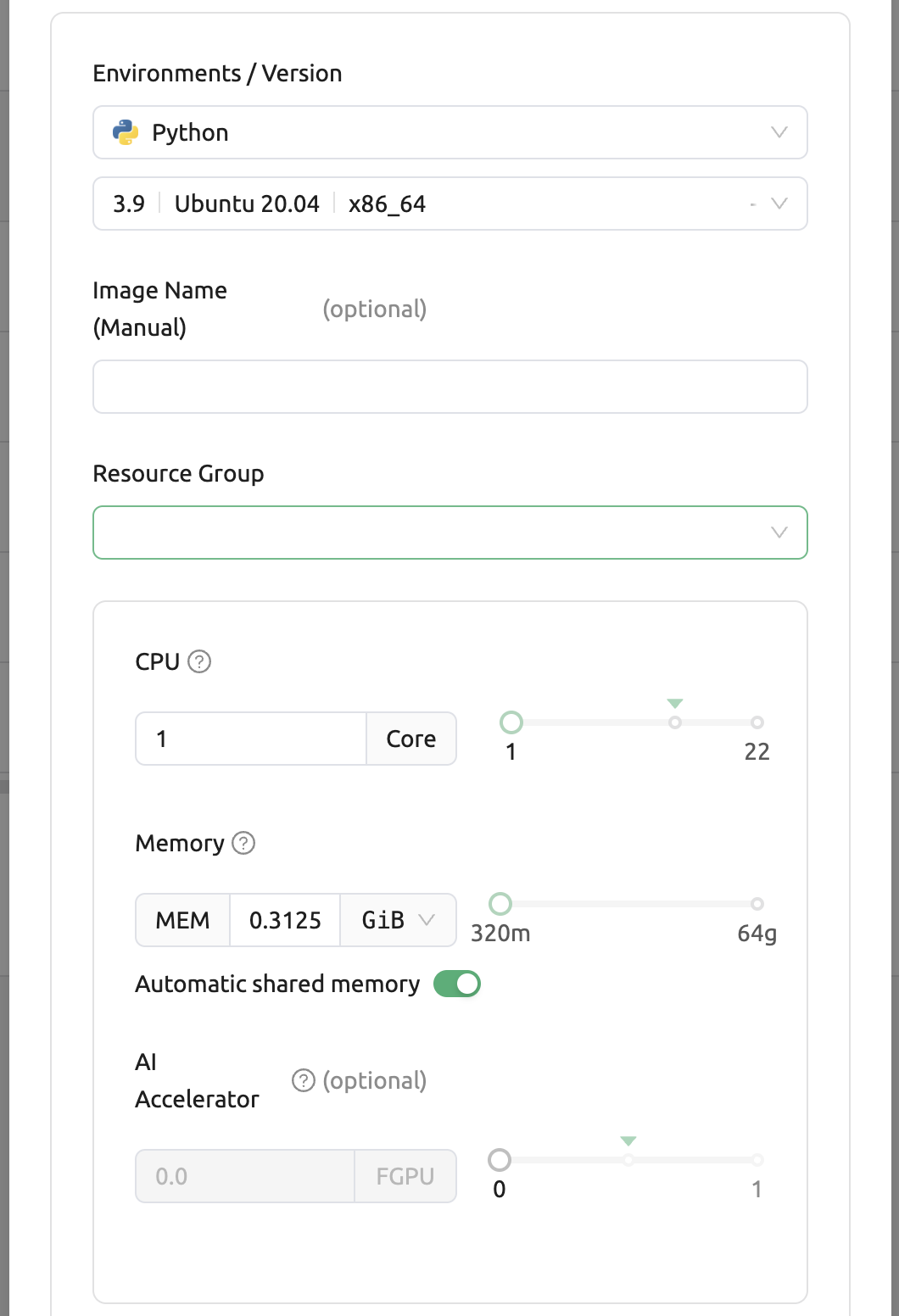
그리고, 이미지 환경과 리소스 그룹을 선택합니다. 리소스 그룹은 모델 서비스에 할당될 수 있는 리소스의 집합입니다.
Environment / Version: 모델 서비스에서 서비스 전용 서버의 실행 환경을 설정할 수 있습니다. 현재는 서비스 내 라우팅이 여러 개여도 단일 실행환경으로만 실행되도록 지원합니다. ( 추후 업데이트 예정 )
CPU: 모델 서비스를 실행하는 라우팅, 즉 연산 세션에 할당할 CPU코어의 수.
RAM: 연산 세션에 할당할 메모리의 용량(GiB)
GPU: 연산 세션에 할당할 GPU 단위
Shared Memory: 연산 세션에 할당할 공유 메모리의 용량(GiB). 연산 세션에 할당할 메모리의 용량보다는 작아야 함
AI Accelerator : AI 가속기 (GPUs 또는 NPUs)의 양입니다. 설정에 의해 수동 이미지 설정이 허용된 경우, 사용자는 선택한 리소스 그룹에 따라 AI 가속기를 선택할 수 있습니다.
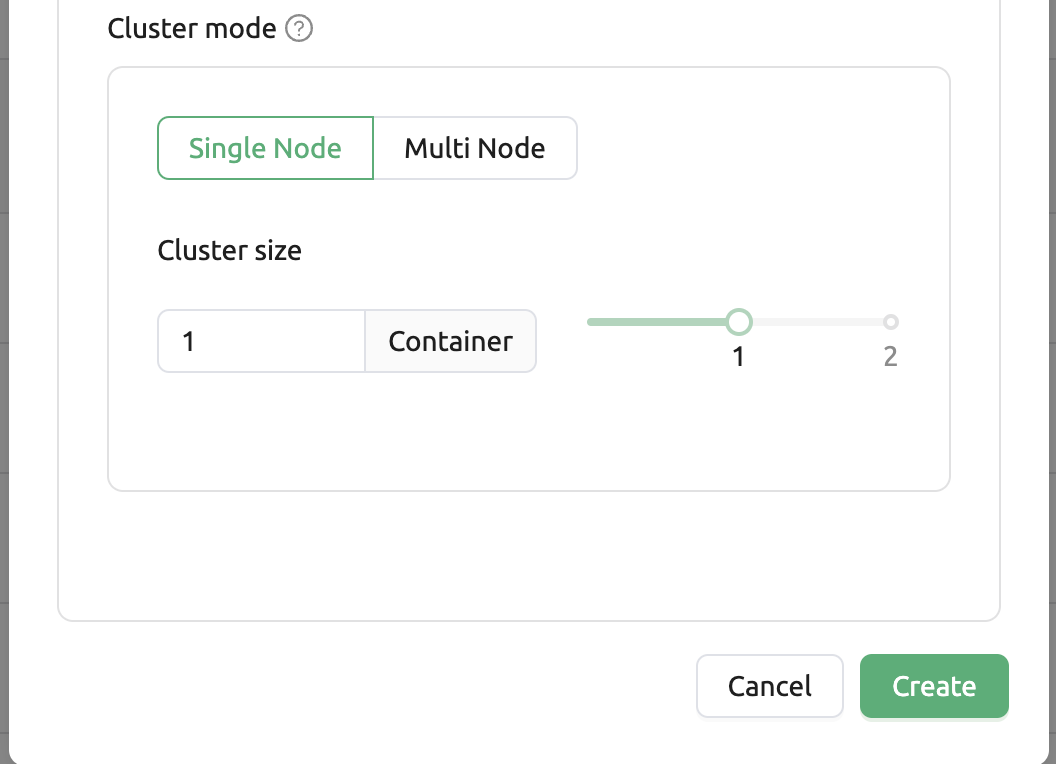
Single Node : 세션을 실행할 때에 관리 노드와 워커 노드들이 하나의 물리 노드 또는 가상 머신에 배치하는 경우입니다.
Multi Node : 세션을 실행할 때 하나의 관리 노드와 하나 이상의 워커 노드가 여러 물리 노드 또는 가상 머신에 나누어 배치되는 경우입니다.
모델 서비스 수정하기
제어 탭에서 톱니바퀴 아이콘을 클릭하면 원하는 세션 수 값을 변경할 수 있는 모달이 뜨게 됩니다. 수정 모달은 모델 서비스를 시작하는 모달과 형태가 동일하며, 이전에 입력했던 필드들이 적용되어 있습니다. 원하는 필드를 수정하고 확인 버튼을 클릭하게 되면, 변경 사항이 적용됩니다.
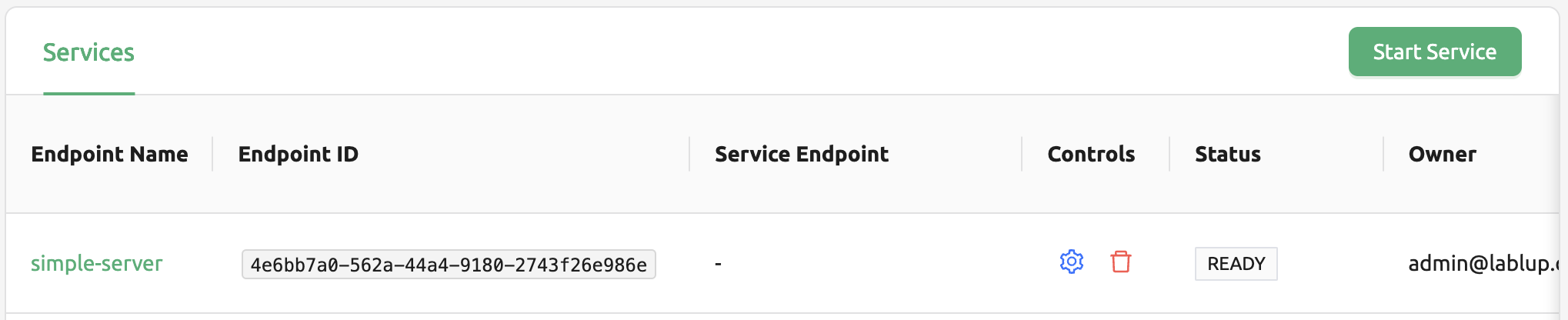
모델 서비스 종료하기
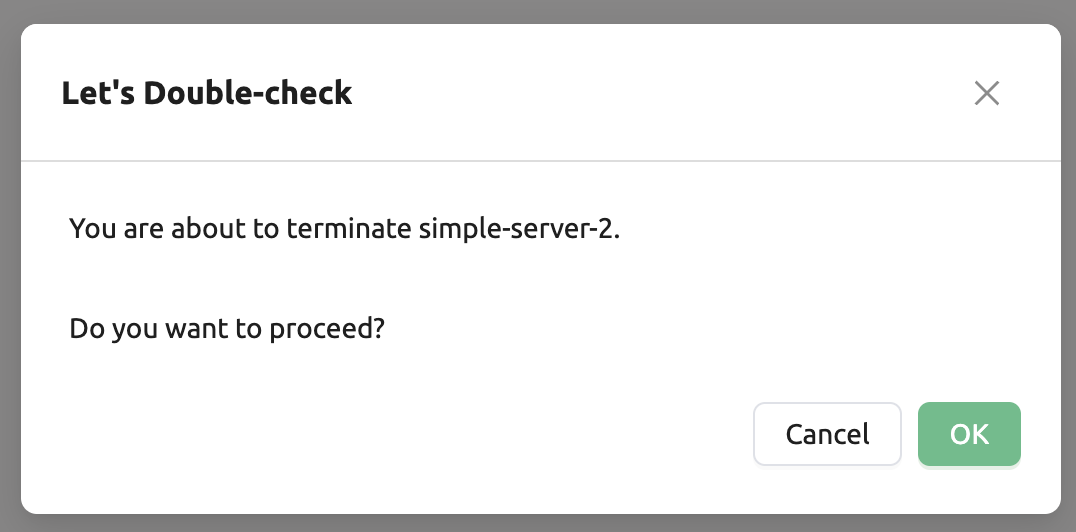
모델 서비스는 주기적으로 스케줄러를 실행하여, 원하는 세션 수와 실제 대응하는 라우팅 수가 원하는 세션 수에 맞춰지도록 스케줄링합니다. 다만, 이 경우 Backend.AI 스케줄러에 부하가 가는 것은 불가피 합니다. 따라서 모델 서비스를 더 이상 사용하지 않는 경우라면, 모델 서비스를 종료하는 것이 좋습니다. 모델 서비스를 종료하려면, 제어 탭에서 휴지통 아이콘을 클릭합니다. 이후 모델 서비스를 종료하는 것이 맞는지 확인하는 모달이 뜨게 됩니다. 확인을 누를 경우 모델 서비스는 종료됩니다. 종료된 모델 서비스의 경우 모델 서비스 목록에서 제거됩니다.
모델 서비스 생성에 실패한 경우
만일 모델 서비스의 상태가 UNHEALTHY 로 되어 있는 경우, 모델 서비스를 정상적으로 실행할 수 없는 상태라고 볼 수 있습니다.
생성이 안 되는 이유 및 해결법은 대개 다음과 같습니다 :
모델 서비스 생성 시 너무 적은 양의 자원을 라우팅에 할당한 경우
해결법: 해당 서비스를 우선 종료하고, 이전 설정보다 많은, 충분한 양의 자원을 할당하도록 설정하여 서비스를 재생성합니다.
모델 정의 파일(
model-definition.yml) 의 형식이 잘못된 경우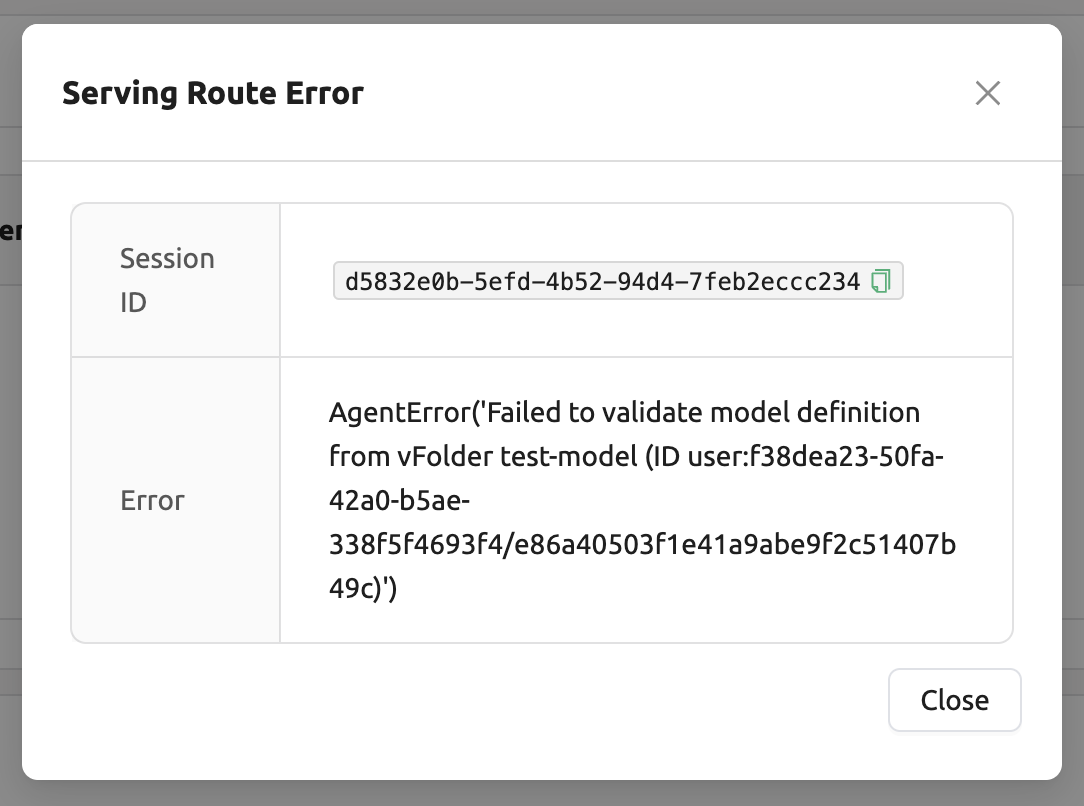
해결법: 모델 정의 파일 형식 을 확인하고, 키-값이 잘못된 경우, 수정하여 저장된 경로에 업로드해 덮어쓰기합니다. 이후 아래와 같이
오류 지우고 재시도버튼을 클릭하여 라우트 정보에 쌓인 에러를 모두 삭제하고, 재시작해 모델 서비스의 라우팅이 정상적으로 동작할 수 있도록 합니다.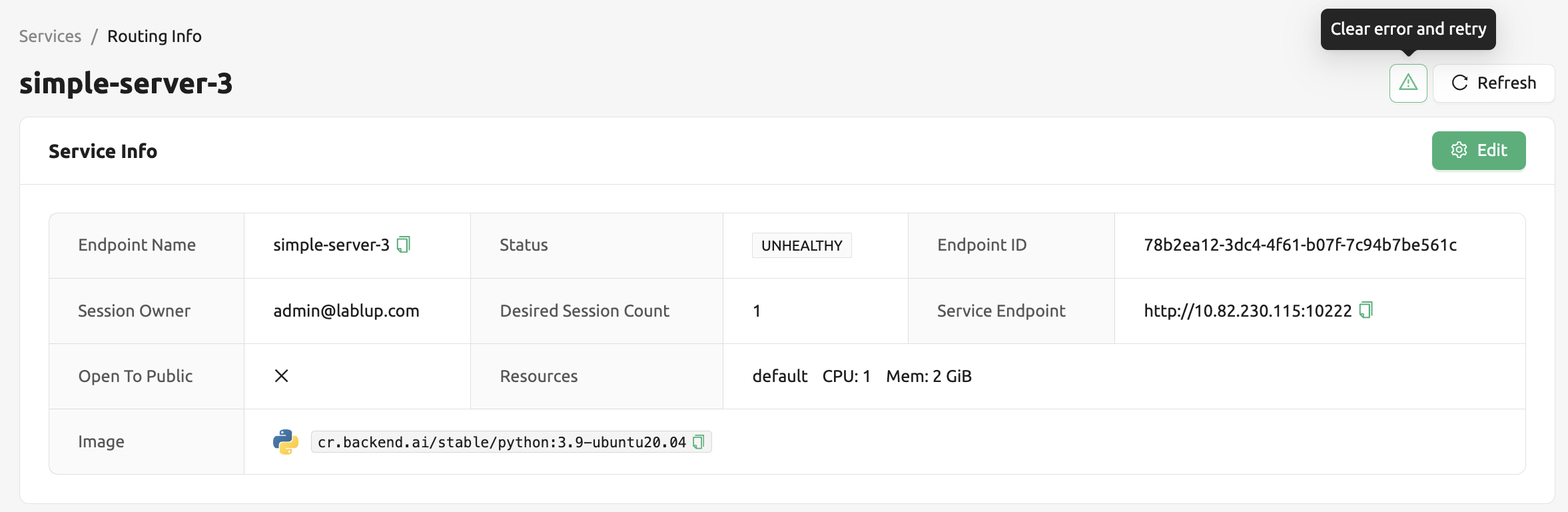
토큰 발급하기
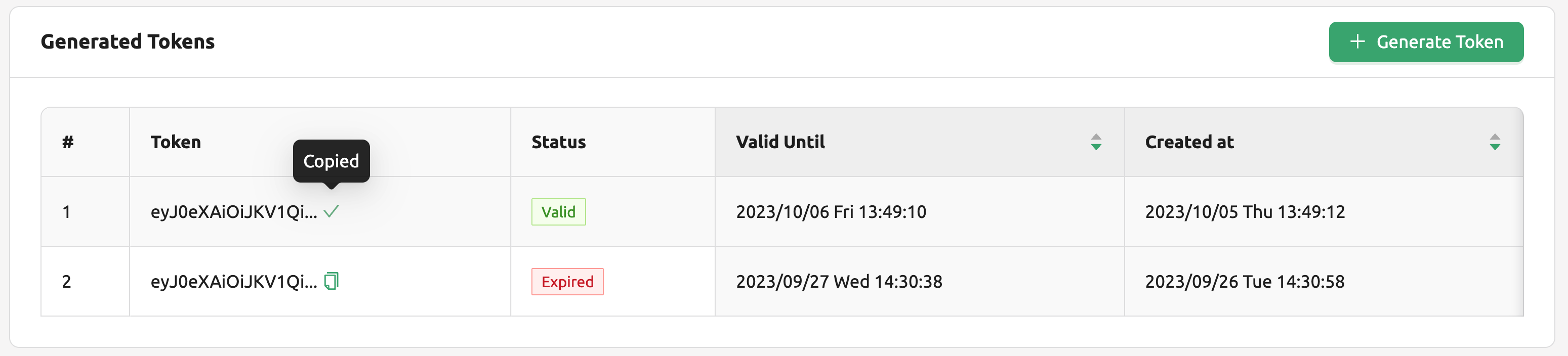
모델 서비스를 성공적으로 실행한 경우, 상태는 HEALTHY 에 속하게 됩니다. 이 경우 모델 서비스 탭에서 해당하는 엔드포인트 명을 클릭해 모델 서비스의 상세 정보를 확인할 수 있습니다. 이후 모델 서비스의 라우팅 정보에서 서비스 엔드포인트를 확인할 수 있는데, 이 엔드포인트는 서비스 생성시 외부에 공개할 수 있는 “Open to Public” 값이 활성화 된 경우, 엔드포인트가 공개되어 별도의 토큰이 없이도 최종 엔드유저가 엔드포인트에 접근할 수 있습니다. 하지만 비활성화 된 경우는 다음과 같이 토큰을 발급하여 토큰을 아래와 같은 형태로 추가해서 서비스가 정상적으로 실행되고 있는지 확인할 수 있습니다.
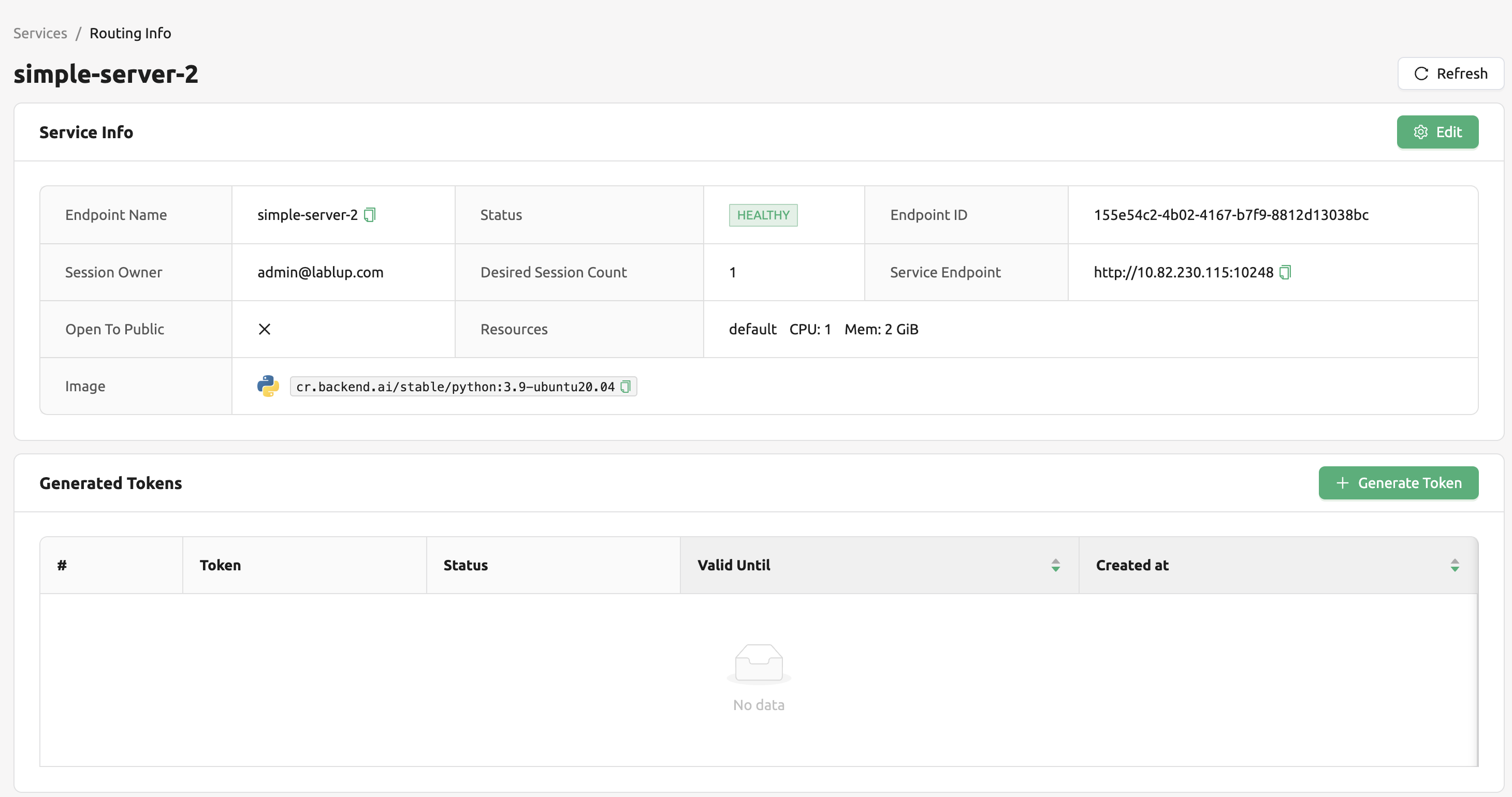
라우팅 정보의 생성된 토큰 목록 우측에 있는 토큰 생성 버튼을 클릭합니다. 이후 토큰 생성을 위한 모달이 뜨면, 만료일을 입력합니다. 이후 발급되는 토큰은 생성된 토큰 목록에 추가됩니다. 토큰 항목의 복사 아이콘을 클릭하여 토큰을 복사하고, 아래와 같은 키 값으로 추가하면 됩니다.
라우팅 정보의 생성된 토큰 목록 우측에 있는 토큰 생성 버튼을 클릭합니다. 이후 토큰 생성을 위한 모달이 뜨면, 만료일을 입력합니다. 이후 발급되는 토큰은 생성된 토큰 목록에 추가됩니다. 토큰 항목의 복사 아이콘을 클릭하여 토큰을 복사하고, 아래와 같은 키의 값으로 추가하면 됩니다.
키 |
값 |
|---|---|
Content-Type |
application/json |
Authorization |
BackendAI |
(엔드유저 전용) 모델 서비스에 대응하는 엔드포인트에 접속하여 서비스 확인하기
모델 서빙이 완료되려면 실제 최종 엔드 유저에게 모델 서비스가 실행되고 있는 서버에 접근할 수 있도록 정보를 공유하여야 합니다. 이 때 서비스 생성시 Open to Public 값이 활성화한 경우라면 라우팅 정보 페이지의 서비스 엔드포인트 값을 공유하면 됩니다. 만일 비활성화 한 채로 서비스를 생성한 경우라면 서비스 엔드포인트 값과 앞서 생성한 토큰 값을 공유하면 됩니다.
curl 명령어를 사용해서 모델 서빙 엔드포인트에 보내는 요청이 제대로 동작하는 지 아닌지 확인할 수 있습니다.
$ export API_TOKEN="<token>"
$ curl -H "Content-Type: application/json" -X GET \
$ -H "Authorization: BackendAI $API_TOKEN" \
$ <model-service-endpoint>
경고
기본적으로 엔드 유저는 엔드포인트에 접근이 가능한 네트워크 망에 있어야 합니다. 만일 폐쇄망에서 서비스를 생성한 경우, 폐쇄망 내 접근이 가능한 엔드 유저만 접근이 가능합니다.